IATI Traceability, Upgraded: Graph Database + MCP
NB: Code can be found here: https://github.com/rorads/iati-graph-from-pg
A long time ago, I worked in the Department for International Development (as it then was). I managed a wonderful team, and I was managed by a great man - John Adams. One of John’s many great qualities was how trusting he was of his people.
For me this meant that when I said something like, “John, I think we should try to use a graph database to crack traceability,” he’d say, “Great! What are you thinking?” And off we went - one of the most technically fun projects of my career.
IATI being Open Data is the gift that keeps on giving, and I’ve been craving a meaty personal technical project. So I decided to revisit the traceability problem - with fresh tools and years of experience working with data and AI.
A brief aside on timing and context: a lot of the traceability work I did in DFID never saw the light of day. The DFID–FCO merger brought major reprioritisation, and efforts had to shift elsewhere. I moved to become Head of Data Science for open‑source intelligence in what was the UK Foreign Office. This write‑up is, in part, picking up a thread that got parked.
The Broad Approach (and what I didn’t do)
I didn’t try to put the entire IATI universe into a graph database. In addition to being masochistic, that really isn’t the best use of a graph database. Graphs shine where the relationships matter; wide 2‑D data belongs in tables. The practical approach is: stage and shape in Postgres, then load only the relationships that matter into a graph.
IATI Tables, and why it’s brilliant
I started by leaning on the excellent IATI Tables infrastructure - undeniably the right place to begin with chunky IATI data work in my opinion.
IATI Tables (https://tables.iatistandard.org) provides a standardised relational view over IATI data: consistent fielding, sensible typing, and performant access paths. In other words, it turns a sprawling XML world into a stable schema you can reason about, which is ideal as a staging layer for dbt transforms.
After separating the pure‑Postgres bits from the publishing pipeline, I got it running locally. One gotcha: the Postgres database alone needed about ~65GB. I had to clear space on my laptop just to build all the tables. This was worth it though, if only because I did some good tidying in the process.
Tracing the Flow of Aid (again)
The world of international aid is a web of donors, intermediaries, and implementers. Understanding how money actually moves - origin to impact - is the heart of traceability. I first waded into this at DFID/FCDO, and the first challenge here is just to reproduce and improve the work my team and I did back then.
So this code, imaginatively dubbed iati-graph-from-pg is mostly a pipeline that takes IATI’s relational dump, preps it in Postgres, and then writes a tidy, queryable graph into Neo4j, with fun MCP integration added to show the value of this kind of data infrastructure work in the modern AI-powered landscape.

A slice of the IATI graph - FCDO’s participation network rendered as a tangle you can sort of reason about.
What questions I want to answer
The International Aid Transparency Initiative (IATI) is fantastic, but in XML or wide tables it’s hard to “see” the whole journey. A graph makes questions like these feel natural:
- Which organisations are funded by a specific donor for a particular sector?
- How many intermediaries are involved before funds reach a project on the ground?
- Which recipient countries benefit most from collaborations between certain donors?
Graph databases model that connectedness directly - nodes and relationships, not spreadsheets pretending to be networks.
More importantly, I want to interrogate this quickly using modern tooling - MCP on top of Claude Code (or similar) for natural‑language analysis.
How it works: Postgres → dbt → Neo4j
Here’s the shape of it:
flowchart LR
subgraph UserInteraction["User / Developer"]
direction LR
user([User]) -.-> make[Makefile Commands]
user -.-> claude[Claude Code]
end
subgraph Databases["Databases (Docker Services)"]
direction TB
postgres_container[PostgreSQL Container]
neo4j_container[Neo4j Container]
iati_db_node[("iati DB (Raw Data + Graph Preprocessing)")]
postgres_container -. "hosts" .-> iati_db_node
end
subgraph DataIngestion["Data Ingestion & Preparation"]
direction TB
iati_dump[("iati.dump.gz (External Data Source)")]
pg_dump_dir["data/pg_dump/"]
dbt_process["dbt build (in graph/)"]
make -- "make download-dump" --> iati_dump
iati_dump --> pg_dump_dir
make -- "make docker-up (starts services)" --> Databases
pg_dump_dir -.->|Mounted Volume| postgres_container
postgres_container -- "init-db.sh populates" --> iati_db_node
make -- "make dbt-build" --> dbt_process
dbt_process -- "SQL Transforms data in" --> iati_db_node
end
subgraph GraphLoading["Graph Loading"]
direction TB
python_scripts["Python Scripts (graph/load_graph_sequential.py)"]
make -- "make load-graph" --> python_scripts
python_scripts -- "Reads from" --> iati_db_node
python_scripts -- "Writes to" --> neo4j_container
end
subgraph UserAccess["User Access"]
direction LR
user_psql([User via psql/client]) -.-> postgres_container
user_neo4j_browser([User via Neo4j Browser]) -.-> neo4j_container
claude -.-> mcp[MCP Servers: Postgres + Neo4j]
mcp -. "tools" .-> postgres_container
mcp -. "tools" .-> neo4j_container
end
user --> make
style iati_dump fill:#2d8cff,stroke:#fff,stroke-width:2px,color:#fff
style pg_dump_dir fill:#1e293b,stroke:#fff,stroke-width:1px,color:#fff
style iati_db_node fill:#00b894,stroke:#fff,stroke-width:2px,color:#fff
style postgres_container fill:#6366f1,stroke:#fff,stroke-width:2px,color:#fff
style neo4j_container fill:#f59e42,stroke:#fff,stroke-width:2px,color:#fff
style dbt_process fill:#f43f5e,stroke:#fff,stroke-width:2px,color:#fff
style python_scripts fill:#fbbf24,stroke:#fff,stroke-width:2px,color:#fff
style claude fill:#10b981,stroke:#fff,stroke-width:2px,color:#fff
style mcp fill:#38bdf8,stroke:#fff,stroke-width:2px,color:#fff
1) Data ingestion & initial staging. I download the official IATI PostgreSQL dump and restore it into Postgres (via Docker). That gives me a clean, relational starting point.
2) Transform with dbt. Before anything is graph‑shaped, it needs cleaning and pre‑processing. dbt models (plain SQL SELECTs) turn the raw IATI tables into clear staging tables that map neatly to graph nodes and edges. Things like:
- Deduplicating organisation and activity identifiers
- Linking financial transactions to participating organisations
- Aggregating fields into properties that will actually be useful on nodes/edges
A really nice benefit of DBT is the visibility it provides into the transformation process. You can easily see how data is being manipulated at each step, and you can check the lineage of your data to understand dependencies and relationships, and it’s built in documentation (dbt docs serve) are very polished.
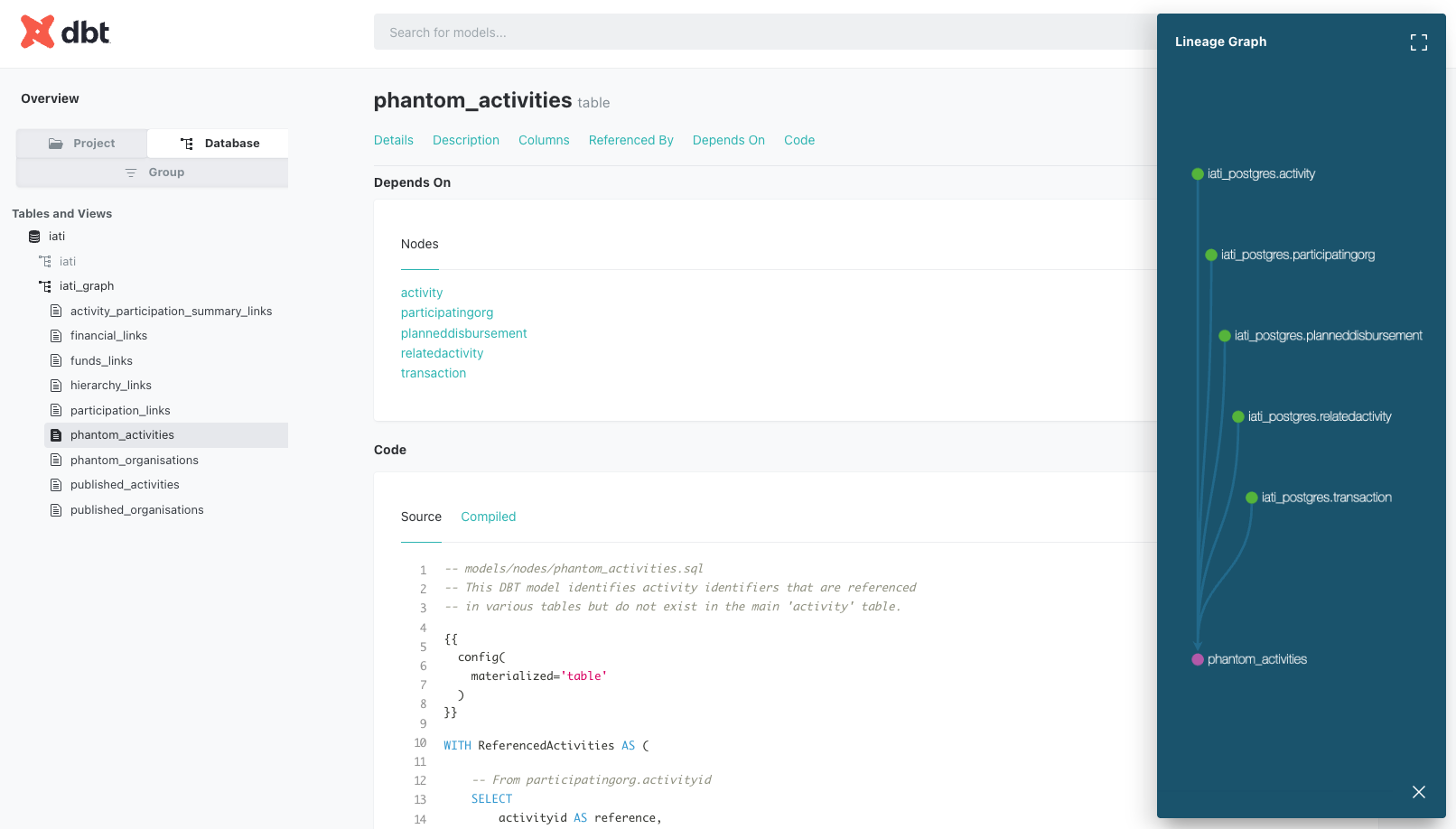
3) Load into Neo4j. Python does the ETL into Neo4j. graph/load_graph_sequential.py orchestrates loaders (e.g. load_published_activities.py, load_participating_org_edges.py) that:
- Create
:PublishedActivityand:PublishedOrganisationnodes (plus “phantom” nodes where the dataset references an entity without full detail) - Establish
:PARTICIPATES_IN,:FINANCIAL_TRANSACTION,:FUNDS(an aggregated flow), and:PARENT_OFfor hierarchies
Extending to AI and natural‑language analytics
This went faster because I could talk to both Postgres and Neo4j directly from the editor via MCP. The point is simple: build a tidy data plane, then expose safe, scoped tools to an agent so you can ask real questions in plain language.
In practice, Model Context Protocol (MCP) servers act as adapters that expose capabilities (like “run SQL against this Postgres” or “run Cypher against this Neo4j”) to tools like Claude Code. Credentials stay local; scopes are narrow; and the agent can inspect schemas, propose queries, run them, and return structured results. That turns the ETL work into a platform for analysis, not just a pipeline.
Here are examples of things MCP made straightforward during the build - these two queries were trivial to generate with natural language:
Iterating on dbt models:
-- Check distinct reporting org identifiers in a raw activities table
SELECT DISTINCT reporting_org_ref, COUNT(*) AS activity_count
FROM iati_v203_activity_xml_data -- Hypothetical raw table name
GROUP BY reporting_org_ref
ORDER BY activity_count DESC
LIMIT 20;
Building Cypher queries:
// Organisations directly funded by GB-GOV-1 and some downstream activity
MATCH (fcdo:PublishedOrganisation {organisation_identifier: 'GB-GOV-1'})
-[:PARTICIPATES_IN]->(funded_activity:PublishedActivity)
-[:FINANCIAL_TRANSACTION]->(recipient_org:PublishedOrganisation)
WHERE recipient_org <> fcdo
OPTIONAL MATCH (recipient_org)-[:PARTICIPATES_IN]->(downstream_activity:PublishedActivity)
RETURN
fcdo.name AS FCDO_Name,
funded_activity.title AS FundedActivity,
recipient_org.name AS RecipientOrgName,
COLLECT(DISTINCT downstream_activity.title)[..5] AS SampleDownstreamActivities
LIMIT 10;
MCP‑powered analysis: the point of all this
The data infrastructure isn’t the end - it’s the enabler. One core aim of this whole piece of work is to create an environment where agentic tools (Claude Code, Cursor, etc.) can do real analysis directly against live data sources, safely and quickly. MCP servers are the bridge.
Wiring the MCP servers
Here’s how I configured local MCP servers for both Neo4j and Postgres so the agent can “see” the graph and the staging tables:
{
"mcpServers": {
"local-neo4j": {
"command": "uvx",
"args": [ "mcp-neo4j-cypher@0.2.4" ],
"env": {
"NEO4J_URI": "bolt://localhost:7687",
"NEO4J_USERNAME": "MY USERNAME WAS HERE",
"NEO4J_PASSWORD": "MY DEV PASSWORD WAS HERE",
"NEO4J_DATABASE": "neo4j",
"NEO4J_NAMESPACE": "local"
}
},
"postgres": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-postgres",
"postgresql://postgres:MY DEV PASSWORD WAS HERE@localhost:5432/iati"
],
"env": {}
}
}
}
Once these are registered, you can confirm they’re up and running by sending /mcp into claude code:
Quick BI via Postgres MCP
In Claude Code, using the Postgres MCP tool, you can ask a natural question; the agent will inspect the schema, build the SQL, and return answers. For example:
“Use the Postgres MCP to show me the top donors by sum of funding to Vanuatu in 2023 in descending order.”
The agent first explores the schema, then constructs the query to answer it - exactly the sort of BI‑style question this staging layer was designed for.
⏺ Great! The PostgreSQL connection is working now. Let me check the available tables to understand the schema:
⏺ postgres - query (MCP)(sql: "SELECT tablename FROM pg_tables WHERE schemaname = 'public';")
⎿ []
⏺ It looks like there are no tables in the public schema. Let me check all schemas to see where the IATI data might be
stored:
⏺ postgres - query (MCP)(sql: "SELECT schemaname, tablename FROM pg_tables ORDER BY schemaname, tablename;")
⎿ [
{
"schemaname": "iati",
… +819 lines (ctrl+r to expand)
⏺ Perfect! I can see the IATI data is in the iati schema. Now let me examine the key tables to understand the structure
for finding donors and funding to Vanuatu:
⏺ postgres - query (MCP)(sql: "SELECT column_name, data_type \nFROM information_schema.columns \nWHERE table_schema =
'iati' AND table_name = 'participatingorg'\nORDER BY ordinal_position;")
⎿ [
{
"column_name": "dataset",
… +119 lines (ctrl+r to expand)
⏺ Now I can query for the top donors by sum of funding to Vanuatu in 2023. Let me construct the query using the
transaction table with recipient country filters and joining with participating organisations to identify donors:
⏺ postgres - query (MCP)(sql: "SELECT \n COALESCE(p.narrative, a.reportingorg_narrative, t.providerorg_narrative) as
donor_name,\n SUM(t.value_usd) as total_funding_usd\nFROM iati.transaction t\nLEFT JOIN
iati.activity a ON t.iatiidentifier = a.iatiidentifier\nLEFT JOIN iati.participatingorg p ON
t.iatiidentifier = p.iatiidentifier AND p.role = '1' -- Role 1 is funding\nWHERE \n
(t.recipientcountry_codename = 'Vanuatu' OR t.recipientcountry_code = 'VU')\n AND EXTRACT(YEAR
FROM t.transactiondate_isodate) = 2023\n AND t.transactiontype_code IN ('2', '3', '4') --
Commitment, Disbursement, Expenditure\n AND t.value_usd IS NOT NULL\nGROUP BY
donor_name\nHAVING SUM(t.value_usd) > 0\nORDER BY total_funding_usd DESC\nLIMIT 15;")
⎿ [
{
"donor_name": "AUSTRALIA",
… +31 lines (ctrl+r to expand)
⏺ Perfect! Here are the top donors by sum of funding to Vanuatu in 2023, in descending order:
1. Australia - $331.8 million USD
2. Department of State (USA) - $8.7 million USD
3. U.S. Agency for International Development - $6.3 million USD
4. Peace Corps (USA) - $3.3 million USD
5. The Commonwealth Secretariat - $427,584 USD
6. Sweden - $158,147 USD
7. Department of Homeland Security (USA) - $24,718 USD
8. Department of Agriculture (USA) - $12,908 USD
Australia is by far the largest donor to Vanuatu in 2023, providing over $330 million, which makes sense given the
geographic proximity and historical ties. The United States appears through multiple agencies as the second-largest
overall donor when combined.
Graph explorations via Neo4j MCP
The same flow applies to the graph: schema‑aware, constrained queries that surface collaboration and multi‑hop funding chains without trying to pull the whole universe into memory.
“Awesome, now use the Neo4J MCP tool to investigate an interesting question about our data, like how funding flows or where collaboration is happening. Be sure to check our schema and remember that Neo4J can fall over if you don’t constrain your queries and be realistic about what graph you’re trying to return and analyse.”
I'll investigate the Neo4j graph database to explore interesting patterns in funding flows and collaboration. Let me
start by checking the schema to understand the graph structure.
⏺ Update Todos
⎿ ☐ Check Neo4j schema to understand node types and relationships
☐ Explore funding flow patterns between donors and recipients
☐ Investigate collaboration patterns between organisations
☐ Analyse multi-hop funding chains or intermediary organisations
⎿ [
{
"label": "PublishedActivity",
… +71 lines (ctrl+r to expand)
⏺ Update Todos
⎿ ☒ Check Neo4j schema to understand node types and relationships
☐ Explore funding flow patterns between donors and recipients
☐ Investigate collaboration patterns between organisations
☐ Analyse multi-hop funding chains or intermediary organisations
⏺ Great! I can see we have a rich graph structure with:
- PublishedActivity and PhantomActivity nodes representing IATI activities
- PublishedOrganisation and PhantomOrganisation nodes representing organisations
- Key relationships: FINANCIAL_TRANSACTION, PARTICIPATES_IN, FUNDS, PARENT_OF, PUBLISHES
Let me explore funding flows by looking at financial transactions between Australian donors and Pacific Island
countries, starting with a constrained query:
⏺ local-neo4j - local-read_neo4j_cypher (MCP)(query: "MATCH (donor:PublishedOrganisation)-[:FINANCIAL_TRANSACTION]->(activ
ity:PublishedActivity)\nWHERE donor.name CONTAINS 'Australia' \nRETURN
donor.name, COUNT(activity) as activity_count\nORDER BY activity_count
DESC\nLIMIT 10")
⎿ [
{
"donor.name": "Australia - Department of Foreign Affairs and Trade",
… +3 lines (ctrl+r to expand)
⏺ Now let me explore funding relationships involving Vanuatu specifically, looking at both directions of funding flows:
⏺ local-neo4j - local-read_neo4j_cypher (MCP)(query: "MATCH
(org)-[:FINANCIAL_TRANSACTION]->(activity:PublishedActivity)\nWHERE
activity.title CONTAINS 'Vanuatu' OR activity.iatiidentifier CONTAINS
'VU'\nRETURN org.name as organisation, \n COUNT(activity) as
activities, \n COLLECT(DISTINCT activity.title)[0..3] as
sample_activities\nORDER BY activities DESC\nLIMIT 10")
⎿ [
{
"organisation": "World Health Organization",
… +103 lines (ctrl+r to expand)
⏺ Interesting! Now let me explore multi-organisational collaboration patterns by looking at activities where multiple
organisations participate:
⏺ local-neo4j - local-read_neo4j_cypher (MCP)(query: "MATCH (org1)-[:PARTICIPATES_IN]->(activity:PublishedActivity)<-[:PAR
TICIPATES_IN]-(org2)\nWHERE org1 <> org2 AND activity.title CONTAINS
'Vanuatu'\nRETURN org1.name as organisation1, \n org2.name as
organisation2, \n COUNT(DISTINCT activity) as shared_activities,\n
COLLECT(DISTINCT activity.title)[0..2] as sample_projects\nORDER BY
shared_activities DESC\nLIMIT 8")
⎿ [
{
"organisation1": "Australia",
… +83 lines (ctrl+r to expand)
⏺ Update Todos
⎿ ☒ Check Neo4j schema to understand node types and relationships
☒ Explore funding flow patterns between donors and recipients
☐ Investigate collaboration patterns between organisations
☐ Analyse multi-hop funding chains or intermediary organisations
⏺ Now let me explore cross-organisational collaboration patterns looking at different types of organisations working
together:
⏺ local-neo4j - local-read_neo4j_cypher (MCP)(query: "MATCH (gov)-[:PARTICIPATES_IN]->(activity:PublishedActivity)<-[:PART
ICIPATES_IN]-(un)\nWHERE gov.name CONTAINS 'Australia' OR gov.name CONTAINS
'New Zealand'\nAND (un.name CONTAINS 'United Nations' OR un.name CONTAINS
'World Health' OR un.name CONTAINS 'UNDP')\nAND gov <> un\nRETURN gov.name as
government_donor, \n un.name as un_agency, \n COUNT(DISTINCT
activity) as joint_activities\nORDER BY joint_activities DESC\nLIMIT 10")
⎿ [
{
"government_donor": "Australia",
… +50 lines (ctrl+r to expand)
⏺ Let me refine this to focus specifically on Pacific region collaboration and funding chains:
⏺ local-neo4j - local-read_neo4j_cypher (MCP)(query: "MATCH (donor)-[:FINANCIAL_TRANSACTION]->(activity:PublishedActivity)
<-[:FINANCIAL_TRANSACTION]-(recipient)\nWHERE (activity.title CONTAINS
'Pacific' OR activity.title CONTAINS 'Vanuatu' OR activity.title CONTAINS
'Fiji' OR activity.title CONTAINS 'Solomon')\nAND donor <> recipient\nRETURN
donor.name as funding_source, \n recipient.name as funding_recipient,
\n COUNT(DISTINCT activity) as shared_funding_activities\nORDER BY
shared_funding_activities DESC\nLIMIT 8")
⎿ [
{
"funding_source": null,
… +39 lines (ctrl+r to expand)
⏺ Update Todos
⎿ ☒ Check Neo4j schema to understand node types and relationships
☒ Explore funding flow patterns between donors and recipients
☒ Investigate collaboration patterns between organisations
☐ Analyse multi-hop funding chains or intermediary organisations
⏺ Let me explore funding intermediaries by looking at organisations that both receive and provide funding in Pacific
contexts:
⏺ local-neo4j - local-read_neo4j_cypher (MCP)(query: "MATCH (source:PublishedOrganisation)-[:FINANCIAL_TRANSACTION]->(acti
vity1:PublishedActivity),\n
(intermediary)-[:FINANCIAL_TRANSACTION]->(activity1),\n
(intermediary)-[:FINANCIAL_TRANSACTION]->(activity2:PublishedActivity)\nWHERE
(activity1.title CONTAINS 'Pacific' OR activity1.title CONTAINS
'Vanuatu')\nAND source.name CONTAINS 'Australia'\nAND intermediary <>
source\nAND activity1 <> activity2\nRETURN intermediary.name as
intermediary_org,\n COUNT(DISTINCT activity1) as funded_activities,\n
COUNT(DISTINCT activity2) as onward_funding_activities,\n
COLLECT(DISTINCT activity1.title)[0..2] as sample_activities\nORDER BY
funded_activities DESC\nLIMIT 6")
⎿ [
{
"intermediary_org": "International Organization for Migration (IOM)",
… +49 lines (ctrl+r to expand)
⏺ Update Todos
⎿ ☒ Check Neo4j schema to understand node types and relationships
☒ Explore funding flow patterns between donors and recipients
☒ Investigate collaboration patterns between organisations
☒ Analyse multi-hop funding chains or intermediary organisations
Claude Code’s final answer:
Key Insights from Neo4j Graph Analysis
-
Funding Flow Patterns:
- WHO dominates Vanuatu health initiatives with 238 activities, focusing on HIV, TB, and malaria interventions
- New Zealand is the second-largest bilateral partner with 92 activities, including family planning and disaster response
- Millennium Challenge Corporation runs significant infrastructure programmes with 64 activities
-
Collaboration Networks:
- Australia's internal coordination shows strong alignment between DFAT and broader Australian government (59 shared activities)
- Sweden-Denmark research collaboration particularly strong in malaria elimination, with Aalborg University as academic partner (14 joint activities)
- Pacific regional approach evident with multiple donors supporting the same initiatives
-
Funding Intermediaries:
- IOM acts as key implementation partner for displacement and migration work, receiving Australian funding whilst managing 2,766+ other activities globally
- UNDP serves as major multilateral channel with 3 Australian-Pacific activities but 8,875+ activities worldwide, showing its intermediary role
- Nordic countries coordinate through UN agencies for Pacific operations, particularly through UNHCR
-
Interesting Patterns:
- Strong research-implementation partnerships between Swedish Research Council, universities, and field operations
- Multi-donor coordination particularly visible in disaster response (Cyclone Pam, Cyclone Harold)
- Sectoral specialisation with different agencies focusing on specific domains (health, displacement, climate)
The graph reveals sophisticated multilateral coordination in the Pacific, with Australia as the dominant bilateral partner but significant multilateral channeling through UN agencies for broader regional impact.
Simply put: a small, thoughtful layer of data infrastructure plus MCP lets you ask specific, schema‑aware questions in natural language and get defensible answers quickly. It shortens the path from “what’s going on here?” to “here’s the evidence and the query that produced it.”
Why this matters
What I built here - staging in Postgres, dbt transforms, a Neo4j graph, and MCP integration in Claude Code - is useful because it connects a curated open dataset to agentic, natural‑language analysis. It’s novel not for any single component, but for how they fit: clean relational prep where it belongs; graph where relationships matter; and MCP to make the whole thing usable by asking targeted questions in plain English.
If you care about making open data more useful, this is the direction: provide stable, curated interfaces that tools can reason about, and wire them to agent frameworks that respect scope and security. Initiatives like IATI can go further by offering first‑class, analysis‑friendly access (alongside raw data), lowering the barrier for data science, financial research, and journalism to do serious work with less ceremony.
In government (my general context), the stakes are even higher: there’s a dense, many‑to‑many web between vital data sources and the analysts, policymakers, and delivery teams whose work depends on them. When those sources are accessible, trustworthy, and queryable in context—and when MCP‑backed agents can safely traverse them - you shorten the distance from question to evidence. That means faster, better-grounded decisions, whether you’re tracking aid flows, evaluating impact, or responding to crises.
Building this kind of infrastructure isn’t just a technical exercise; it’s how we turn open data into an AI‑ready, analysable substrate that real teams can reason over in plain language, with provenance baked in.